

Vamos a ver de forma resumida algunos parámetros, conceptos y técnicas relacionadas con la calidad de imagen de una producción de vídeo digital.

Grabando con una Blackmagic. Foto: Kei Takahashi (CC BY-ND 2.0)
Nos han preguntado en varias ocasiones ‘¿cuál sería la cámara recomendada para conseguir la máxima calidad de imagen posible en youtube?’
Es decir, la idea es la siguiente: youtube (o cualquier otra plataforma similar) realiza una compresión de la señal de vídeo, de forma que da igual si el vídeo original tiene una calidad extrema o una calidad media, el vídeo final publicado tendrá la misma calidad de imagen en los dos casos (lógicamente si el vídeo original está por debajo de los parámetros de calidad de youtube, el resultado final será malo).
Por lo tanto, según ese razonamiento, si vamos a publicar en youtube no valdría la pena usar una cámara cuya calidad de imagen esté muy por encima de esos parámetros de calidad, de ese límite que impone youtube.
Esto no es realmente así, y a lo largo de este artículo vamos a ir viendo algunos conceptos relacionados con el vídeo digital y la calidad de imagen.
También veremos un poco algunas diferencias entre cámaras de vídeo, por ejemplo qué ventajas ofrecen las cámaras de gama alta especializadas en vídeo.
Es un artículo bastante técnico, aunque hemos intentado resumir y simplificar mucho. La idea es ofrecer una especie de guía o referencia básica de conceptos sobre vídeo digital, que sirva de punto de partida para quien quiera profundizar.
Aquí tienes el índice de contenidos por si quieres mirar sólo algún apartado en concreto o si quieres saltar directamente a las conclusiones:
- Criterios de calidad de imagen (vídeo)
- Cómo se genera la información de vídeo
- Qué volumen de información genera el vídeo
- Cómo se almacena el vídeo: formatos, codecs, contenedores
- Calidad de vídeo y su relación con la tasa de bits
- Técnicas de compresión de la información de vídeo (intraframe, interframe, chroma subsampling…)
- Rango dinámico y curvas de corrección de gamma (curvas logarítmicas)
- Calidad de vídeo en la fase de edición (corrección de color, etalonaje…)
- Comparativa de cámaras según la tasa de bits que generan
- Resumen y conclusiones
Criterios de calidad de imagen en vídeo
Es difícil cuantificar la calidad técnica de un vídeo porque intervienen muchos factores subjetivos, pero a efectos de lo que trata este artículo la calidad de imagen en general (y de la imagen de vídeo) estaría relacionada con:
- Resolución y nitidez. No tanto la resolución en cuanto a número de píxels, sino a que la imagen tenga un nivel de detalle adecuado y que esos detalles tengan nitidez
- Rango dinámico. Es decir, poder mostrar en una misma escena detalle en las partes más oscuras y en las más brillantes. Tradicionalmente el vídeo ha estado muy limitado en cuanto a rango dinámico con respecto al cine.
- Color. Fidelidad de color con respecto a la realidad o con respecto a lo que se quiere transmitir
La calidad del vídeo (calidad de imagen) dependerá, entre otras cosas, de:
- Las condiciones de iluminación
- La calidad óptica de los objetivos
- El sensor de la cámara
- El procesador de la cámara
- El proceso de edición
- El formato de distribución del producto final
Cómo se genera la información de vídeo
Para entender un poco el proceso vamos a comenzar desde el principio, desde el momento en que se genera la imagen en el sensor de la cámara.
El funcionamiento de un sensor electrónico lo puedes ver en este otro artículo. Tanto para fotografía como para vídeo el proceso inicial es similar.
En el caso de vídeo no se utiliza el obturador mecánico, la luz llega constantemente al sensor y éste la recoge durante el tiempo de exposición programado, pasado ese tiempo se lee la información (cantidad de luz que ha recogido la celda) y se vacían las celdas, para comenzar de nuevo en el siguiente ciclo (siguiente fotograma)
Debido a limitaciones técnicas y de costes, en la mayoría de las cámaras este proceso de lectura de cada fotograma se realiza con la técnica de rolling shutter, que consiste en que el encendido, lectura y apagado de las celdas es progresivo, de arriba a abajo fila por fila. Cada celda está ‘abierta‘ recogiendo luz exactamente el tiempo de exposición indicado, pero no todas al mismo tiempo. Algunas cámaras, muy pocas, utilizan la técnica de global shutter, en la que todas las celdas del sensor se abren a la vez, se lee toda la información del fotograma, se vacían todas a la vez… y se pasa al siguiente fotograma comenzando de nuevo el ciclo.
Cada celda del sensor recoge la información de alguno de los colores primarios (rojo, verde o azul). Esa matriz tiene una distribución siguiendo un patrón de bayer o alguna otra estructura similar.
El procesador de la cámara hace la magia y convierte esa matriz de puntos de color en una matriz de píxels (el proceso se conoce como interpolación cromática o demosacing en inglés). La diferencia tras el proceso es que cada píxel tiene ahora una información completa de color (una cantidad de rojo + una cantidad de azul + una cantidad de verde).
El rango de posibles valores para cada color (canal) viene determinado por el número de bits con los que se codifica (8, 10, 12..). El número de bits se conoce como profundidad de color, color depth. Cuanto mayor es el número de bits, más fina es la separación entre dos niveles, es decir, se pueden representar más tonalidades diferentes del mismo color:
8bits -> 0-255 (256 niveles diferentes)
10bits -> 0-1023 (1024 niveles diferentes)
Como hemos dicho, un píxel de la imagen final está representado por una combinación de sus componentes R, G y B.
Por ejemplo, para una profundidad de color de 8 bits, cada pixel puede representar:
8×3 = 24 bits, es decir, 16.8 millones de colores diferentes
O para una profundidad de color de 10bits:
10×3 = 30 bits, es decir, 1073.7 millones de colores diferentes
Otra de las tareas que tiene que hacer el procesador es el escalado de resolución. En el caso de las cámaras de fotos que graban vídeo, el sensor tiene normalmente mucha más resolución, genera muchos más píxels de los que utiliza cada fotograma de vídeo. Por lo tanto hay que hacer un escalado, bien por diezmado (descartando píxels) o por algún tipo de algoritmo de muestreo, promediado, etc.
Esos procesos que realiza el sensor (interpolación cromática, codificación binaria y escalado) ya provocan de partida pérdida de información (o al menos interviene cierta interpretación) con respecto a la imagen real que llega de la escena. Sin embargo los procesadores de las cámaras actuales suelen usar algoritmos muy buenos para conseguir un resultado óptimo.
El trabajo del procesador de la cámara no termina ahí, necesita codificar / comprimir la información de vídeo para generar un fichero de vídeo en algún formato estándar.
Para saber por qué hay que comprimir la información de vídeo tenemos que ver el siguiente apartado.
Volumen de información
El volumen de información que genera una secuencia en movimiento es enorme. Vamos a hacer unos cálculos sencillos para hacernos una idea. Supongamos una grabación típica con los siguientes parámetros:
- Formato Full HD (1920 x 1080 px)
- Profundidad de color: 8bits (esto viene fijado por el sensor / procesador de la cámara)
- Fotogramas por segundo (frame rate): 30fps
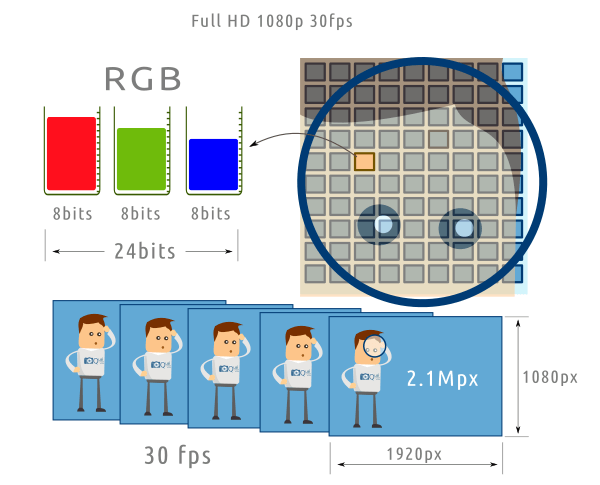
Información que se genera:
- 1920 x 1080 = 2073600 píxels (2.1Mpx) por fotograma
- 2.1Mpx x 24 bits (8 bits para rojo, 8 para verde, 8 para azul) = 50.4Mbits por fotograma
- 50.4Mbits x 30fps = 1512Mbits por segundo (Mbps)
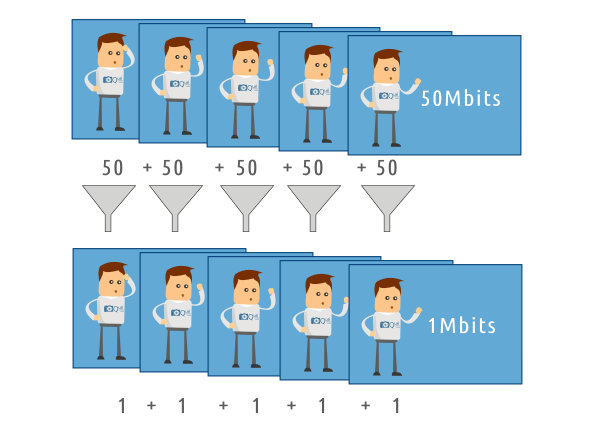
Es decir, aproximadamente 185MB/s (1 byte = 8 bits). Esta sería la tasa de bits (bitrate) de la secuencia de vídeo sin aplicar ningún tipo de compresión.
¿Cuánto ocuparía una secuencia de 1 minuto?
185MB/s x 60s = 11GB/min
Por lo tanto, 1 hora de grabación: 660GB/h
Un volumen de información tan grande es difícil de manejar por limitaciones técnicas o por los costes asociados:
- En el caso de una cámara con tarjeta SD, la cantidad de información por segundo viene limitada por la velocidad de escritura de la tarjeta
- También la limitación de capacidad de almacenamiento (tarjetas, discos duros, etc.)
- En el caso de transmisión de información (por internet por ejemplo) el ancho de banda necesario es muy grande y sería muy caro transmitir esa información (en dinero o en tiempo). No valdría para transmitir en tiempo real (streaming)
- Etc, etc..
Sin embargo, en todo ese volumen de datos hay mucha información redundante. Utilizando algoritmos de compresión se puede reducir la cantidad de datos sin pérdida de información.
Por otra parte, la visión humana tiene una serie de limitaciones o imperfecciones que se pueden aprovechar para reducir todavía más la cantidad de datos, sin que afecte significativamente a la calidad de imagen (o mejor dicho a la percepción que la visión humana tiene sobre esa imagen)
El procesador de la cámara utiliza un codec (codificador / compresor) para comprimir la señal de vídeo y generar una tasa de bits más baja.
Codecs, formatos, contenedores
Esto tiene que ver por una parte con los algoritmos de codificación y compresión, y por otra parte con los estándares que permiten intercambiar información usando esos algoritmos.
Los algoritmos o formatos de codificación son estándares que incluyen las reglas y operaciones matemáticas para trabajar con la información de vídeo. El formato de codificación dice cómo hay que comprimir y codificar la información original (y también cómo se descomprime y descodifica para obtener de nuevo la información inicial). Un formato de codificación de vídeo es por ejemplo h.264, AVCHD, VP9, MPEG-2, MPEG-4 part 2…
Un codec (codificador-descodificador) es un programa informático concreto (software) que se encarga de aplicar un formato de codificación. Un codec puede ser por ejemplo más eficiente que otro a la hora de generar el resultado final. Ejemplos de codecs serían por ejemplo Quicktime h.264, x264, Fraunhofer IIS H.264… (todos ellos codifican en formato h.264)
En el caso de las cámaras, el codec (los codecs) van programados en el procesador, normalmente a través del firmware de la cámara, y en este escenario la mayoría de las veces no se hace distinción entre codec y formato de codificación.
Los contenedores son estándares para distribuir un determinado producto multimedia. En el caso del vídeo, los contenedores incluyen la información de vídeo propiamente dicha, la información de audio, información adicional sobre formatos de codificación, subtítulos, metainformación de títulos y menús, etc.
Cada contenedor está orientado a un tipo de distribución o uso, por ejemplo:
- Contenedores orientados a distribución online (streaming): MP4
- Contenedores para consumo local (p.e. ver una película guardada previamente en un disco duro): MOV, MKV, AVI
- Contenedores para DVD: MPEG, VOB
El contenedor a veces recibe el nombre de formato (por la extensión del fichero). Se puede confundir con el ‘formato de codificación‘ pero son cosas diferentes. Es decir, se dice por ejemplo: este vídeo está en formato MP4 (contenedor MP4), pero internamente el formato de codificación del vídeo puede estar por ejemplo en h.264
Más sobre los codecs MPEG (inglés): Understanding MPEG-2, MPEG-4, H.264, AVCHD and H.265
Calidad de vídeo y tasa de bits
La tasa de bits (bitrate) está muy relacionada con la calidad del vídeo, aunque dependerá del tipo de codificación y de la eficiencia del codec. En cada situación hay que encontrar un compromiso entre calidad y recursos necesarios para alcanzar esa calidad.
¿Con qué tasas de bits se consigue una calidad razonablemente buena?
Por ejemplo para youtube se recomiendan estas tasas de bits:
- Para Full HD (1080p): 8Mbps (para 24-30fps) y 12Mbps (para 50-60fps)
- Para 4K (2160p): 35-45Mbps (para 24-30fps) y 53-68Mbps (para 50-60fps)
Si subimos vídeos con tasas superiores no se notará mejora de calidad apreciable en el producto final, porque el codec de youtube generará el vídeo que aparece publicado en su plataforma para esas tasas de bits, que considera adecuadas para una buena calidad de reproducción.
Recuerda el ejemplo inicial:
1080p / 8bits / 30fps: 1512Mbps (sin ningún tipo de compresión)
1080p / 8bits / 30fps: 8Mbps (con compresión para una calidad aceptable en streaming)
Como ves, el ratio de compresión es altísimo, y sin embargo la calidad que se aprecia en los vídeos de youtube es relativamente buena en la mayoría de los casos.
¿Cómo se consigue comprimir tanto la información de vídeo?
Cada formato de codificación (o codec para simplificar) utiliza diferentes algoritmos y técnicas de compresión de vídeo. Aquí vamos a ver algunas de esas técnicas y cómo pueden afectar a la calidad.
Compresión sin pérdida de información (lossless)
Este tipo de algoritmos funciona de forma similar a los algoritmos de compresión de ficheros (ZIP, RAR, etc.). El funcionamiento se basa en eliminar la redundancia que contiene la información original, pero de tal forma que se puede recuperar posteriormente en su totalidad.
Un ejemplo sencillo de entender sería el siguiente: imagina una escena en la que toda la imagen es de un único color, por ejemplo verde. La información original sería por ejemplo 2.1 millones de pixels, cada uno codificado con 24bits de color (un montón de MB de datos). Sin embargo, esa misma imagen se puede codificar indicando el color del primer píxel y luego indicando cuántos píxels se repiten en secuencia (en este ejemplo 2.1 millones, ya que son todos iguales). El resultado es un fichero de 5-10 bytes. La información de la imagen se puede recuperar perfectamente a partir de esos 5-10 bytes y obtendríamos exactamente la misma información inicial.
Lógicamente en el mundo real no se pueden conseguir esos rendimientos. De hecho con este tipo de compresión se suele obtener una eficiencia bastante baja en vídeo, y hay que valorar también si compensa el tiempo de procesamiento.
Compresión con pérdida de información (lossy)
Prácticamente todas las cámaras utilizan codecs que comprimen los datos con pérdida de información. Sólo en las producciones cinematográficas o producciones de vídeo de alto presupuesto se trabaja con formatos sin compresión o con formatos de compresión sin pérdida de información.
Hay muchas técnicas y algoritmos para conseguir la compresión de vídeo con la menor pérdida posible de calidad de imagen. Los algoritmos se basan en dos tipos de compresión: compresión intraframe y compresión interframe, además se usa mucho la técnica de submuestreo de crominancia (chroma subsampling).
Compresión intraframe (compresión espacial)
Cada fotograma individual (podemos imaginarlo como una imagen RAW que viene del sensor) se comprime siguiendo un algoritmo similar a la compresión JPEG.
Es decir, en lugar de tener una secuencia de imágenes RAW con un volumen de información muy grande, tendremos una secuencia de imágenes ‘JPEG’. El ratio de compresión se puede ajustar para conseguir el equilibrio entre calidad de imagen y volumen final de información (tasa de bits)
Codecs que implementan este tipo de compresión: ALL-I, ProRes..
Compresión interframe (compresión temporal)
Este tipo de compresión se basa en que en la mayoría de las escenas de vídeo tienen redundancia espacial y temporal a lo largo de la secuencia. Es decir, en el mundo real los objetos no pueden moverse de un punto a otro de forma instantánea, por lo que entre un fotograma y el siguiente es muy probable que una gran parte de la escena sea muy similar.
La compresión interframe lo que hace es coger un fotograma completo como referencia (fotograma I, keyframe, etc.) y lo compara con los siguientes fotogramas para ver qué diferencias hay. Para cada uno de esos fotogramas sólo se almacena la información de la diferencia, no la información completa.
El ciclo se repite para un número determinado de fotogramas. Los fotogramas que intervienen en cada ciclo forman un grupo de fotogramas (GOP – group of pictures)
En el caso de MPEG por ejemplo se utiliza una secuencia IPB. Hay un fotograma completo que sirve de referencia. Varios fotogramas después se genera un fotograma P que almacena una predicción de la escena. Y entre esos dos fotogramas están los fotogramas B, que contienen información de los objetos en movimiento.
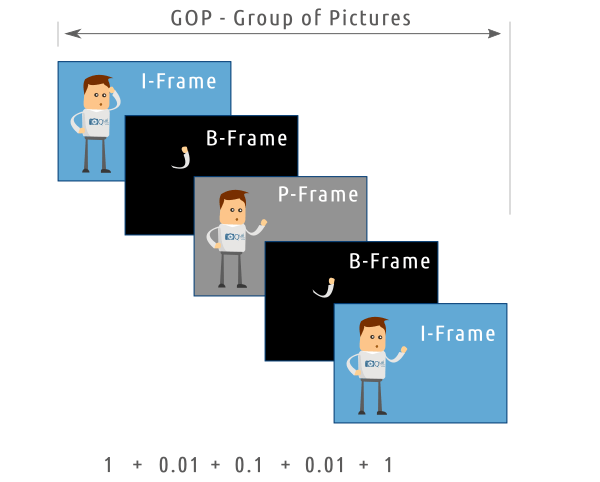
Cuanto mayor sea el grupo de fotogramas (Long GOP) mayor será el ratio de compresión, pero habrá más probabilidades de perder fidelidad con respecto a la escena real. Los valores de configuración de GOP se pueden ajustar, dependiendo del tipo de escenas que contiene el vídeo y de la tasa de bits que necesitemos generar.
En general, la eficiencia de la compresión interframe es mucho más alta que la de la compresión intraframe, para un resultado similar en cuanto a calidad de imagen.
Tiene algunas desventajas: por ejemplo si la señal de vídeo contiene inicialmente mucho ruido (que es algo aleatorio que no tiene la inercia de los objetos reales) la compresión interframe puede producir artefactos no deseados. A la hora de editar necesita más capacidad de procesamiento, porque para reconstruir un determinado fotograma es necesario leer la información de fotogramas anteriores y posteriores.
El ejemplo típico de codec interframe sería h.264 (MPEG-4 parte 10), el codec más utilizado a nivel mundial debido a internet y las plataformas de publicación de vídeos (youtube, vimeo, etc.)
Submuestreo de crominancia (chroma subsampling)
Esta técnica es independiente de las anteriores y está basada en la fisiología del ojo humano: en la retina hay dos tipos de fotorreceptores: bastones y conos. Los bastones detectan niveles de luz (ven en blanco y negro) mientras que los conos detectan el color. La proporción de bastones es mucho mayor, en una relación aproximada de 20:1 (20 bastones por cada cono)
Dicho de otra forma, la visión humana da mucha más importancia a los niveles de luz (niveles de grises) que al color. Por eso podemos ver y entender perfectamente fotografías y películas en blanco y negro.
¿Cómo se puede aprovechar esto?
La información de color de cada píxel la podemos ver matemáticamente como las coordenadas en un sistema tridimensional RGB. Un eje es el canal rojo, otro eje perpendicular el verde y otro eje perpendicular el azul. El conjunto de coordenadas (colores que se pueden representar) se puede visualizar como un volumen de colores posibles.
No es el único sistema de representación. Cada punto (color individual) se puede representar como una combinación de luminancia y crominancia (información de nivel de luz + información de color). La información de color forma dos ejes perpendiculares al de luminancia (Y). Los canales de crominancia se suelen llamar Cb y Cr en el mundo digital. Pasar de un sistema de coordenadas a otro es muy sencillo.
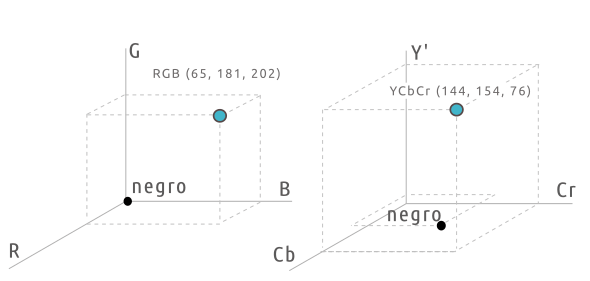
La ventaja de trabajar con luminancia y crominancia es que se pueden manipular esos canales por separado. Lo que interesa es mantener la luminancia tal cual, pero aplicar algún tipo de compresión a los canales de crominancia.
La técnica más utilizada es el submuestreo de crominancia (chroma subsampling). Como en cualquier muestreo, se toma un valor como representativo de un conjunto. En este caso, en lugar de guardar la información de croma de todos los píxels, sólo se guarda la de algunos de ellos. Hay diferentes esquemas, normalmente se aplican a partir de una cuadrícula de 4×2 píxels. Los más utilizados:
4:4:4 (no hay ningún tipo de muestreo, se guarda toda la información de crominancia)
4:2:2 (se toman como referencia los píxels 1, 3, 5, 7. Sólo se almacenan 4 valores de color, un 50% de la información de color)
4:2:0 (en lugar de los 8 valores posibles de crominancia sólo se almacenan 2, correspondientes al píxel 1 y 3 de la cuadrícula, es decir, sólo se guarda el 25% de la información de color)
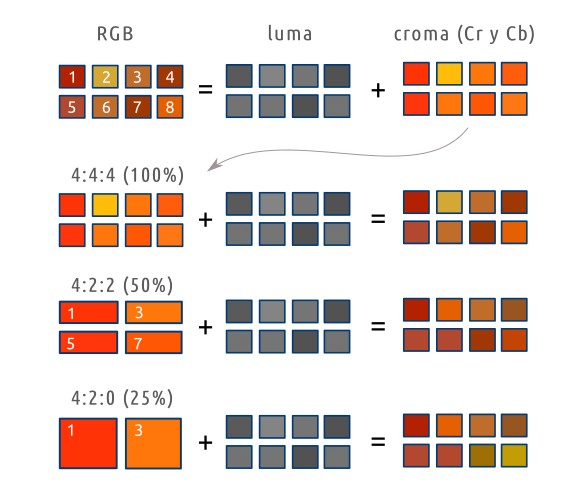
En la práctica no es exactamente así, porque se aplican patrones que combinan los canales Cr/Cb, pero a efectos prácticos el resultado final es una reducción de la cantidad de información.
El submuestreo de croma funciona muy bien, en la mayoría de las escenas o imágenes es prácticamente imposible para el ojo humano distinguir si se ha aplicado o no muestreo. Por ejemplo, mira este trozo de imagen, ampliada hasta el nivel de pixels, que corresponde con el original (4:4:4), un submuestreo 4:2:2 y un submuestreo 4:2:0. Las tres imágenes, sin ampliar a este nivel son indistinguibles. Aquí puedes apreciar algunos cambios de tonalidad por ejemplo en la parte inferior izquierda.

Donde más se nota es por ejemplo en los bordes de los objetos que aparecen en la escena. Dependiendo de la escena se pueden llegar a notar ciertos halos en los bordes y si el submuestreo es muy grande puede afectar bastante al editar escenas con chroma key (el fondo verde situado detrás de los protagonistas de la escena, que se sustituye en edición por otro fondo diferente)
En las producciones cinematográficas, donde se suelen aplicar efectos especiales sobre escenas grabadas en chroma key, es necesario grabar con formatos sin muestreo de croma (4:4:4) para conseguir un resultado óptimo.
Prácticamente todas las cámaras graban con un esquema 4:2:0 o similar (25% de la información de croma), excepto las cámaras especializadas de alta gama para vídeo o para cine digital, que pueden generar 4:2:2 o 4:4:4
Muchas cámaras permiten sacar la señal de vídeo con menos compresión a través del conector HDMI o similar. Por ejemplo algunas cámaras graban en 4:2:0 (en la SD interna) pero generan 4:2:2 en la salida HDMI, que puede ser conectada a un grabador de vídeo externo para conseguir un material base de más calidad.
Rango dinámico, perfiles de color y curvas de corrección de gamma
Este apartado trata brevemente sobre las técnicas que se utilizan para conseguir alto rango dinámico en vídeo.
Una imagen (o vídeo) con alto rango dinámico es la que es capaz de mostrar detalle tanto en las sombras como en las altas luces en una escena en la que hay mucha diferencia de luz (entre la zona más iluminada y la más oscura). El rango dinámico se mide en nits o en pasos de luz.
La visión humana es capaz de captar un rango dinámico de 20-24 pasos de luz en una determinada escena. En ese enlace puedes ver cómo funciona la visión humana y la diferencia entre el proceso de visión (cerebro) y el funcionamiento del ojo.
Las cámaras actuales con sensores grandes (micro 4/3, APS-C, Super 35, Full Frame) pueden tener rangos dinámicos del orden de 10 a 14 pasos de luz (explicación detallada del rango dinámico en cámaras).
Uno de los problemas en vídeo es que por cada paso adicional de rango dinámico se aumenta mucho la cantidad de información que se necesitaría recoger de la escena. Si se quisiera almacenar toda esa información, los 8 bits por canal de color se quedan cortos y habría que pasar a 10 o 12 bits de profundidad de color. Eso es un volumen de información muy muy grande.
Sin embargo hay que tener en cuenta varios factores:
- En primer lugar, la visión humana funciona mucho mejor en el rango de las sombras que en el de las altas luces. Vemos mucho más detalle en la parte de sombras. Mucha de la información de altas luces es redundante para nosotros porque nuestro sistema de visión no tiene tanta ‘resolución’ en esas zonas de más brillo.
- En segundo lugar, en la industria de la televisión (desde la implantación de HD, alta definición) y por extensión en toda la industria audiovisual se utiliza el estándar BT.709, que define un determinado espacio de color y un determinado rango dinámico. Prácticamente todos los televisores, monitores y pantallas LCD (incluyendo las de las cámaras) siguen el estándar BT.709, que cubre unos 6-7 pasos de rango dinámico.
Por el momento no se pueden representar los 14 pasos de rango dinámico (salvo algunos monitores especializados). El usuario que ve el producto final sólo puede apreciar esos 6-7 pasos.
La ventaja de poder grabar 12-14 pasos de rango dinámico es que permite recuperar sombras y altas luces, y dar más contraste a la imagen sin que se quemen las altas luces ni se empasten las sombras. Se puede conseguir una imagen de vídeo que la visión humana interpreta como natural, con mucho detalle en las sombras, con detalle también en las luces, como si tuviera un rango dinámico mucho más grande.
Es decir, se puede empaquetar el aspecto que tendría una escena real en un espacio de color más restringido como es el BT.709
Entonces, volviendo al problema inicial: Nos interesa que la cámara recoja esos 12-14 pasos de rango dinámico, pero no tenemos recursos para almacenar y gestionar el tremendo volumen de información que se va a generar.
Para resolver este problema se utilizan las curvas de corrección de gamma. Básicamente lo que hacen estas curvas es comprimir la parte de altas luces e intentar mantener la linealidad del sensor en la zona de sombras.
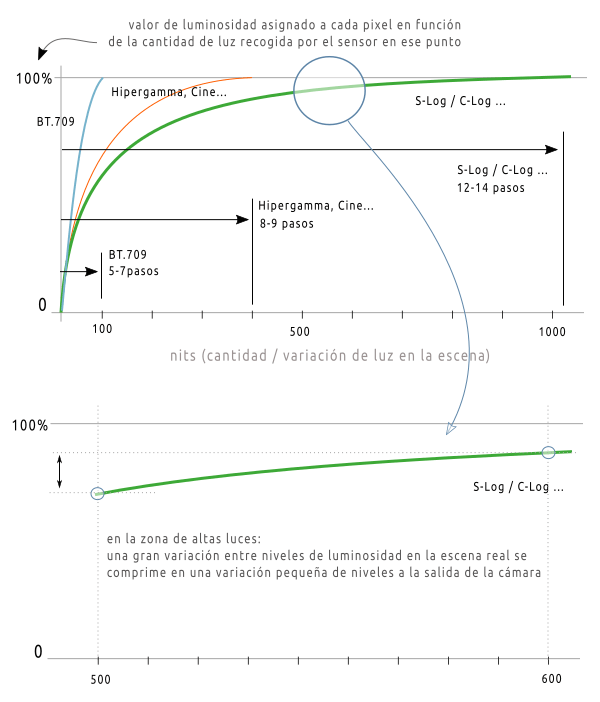
Es decir, de la información que ha recogido el sensor, las pequeñas variaciones de luminancia en las zonas de sombra se siguen procesando y almacenando tal cual, pero las variaciones de luminancia en altas luces se comprimen, ya que de todas formas el ojo humano no va a captar o no va a dar importancia a esos detalles en las zonas de más luz.
El rango dinámico sigue siendo muy grande, pero se le da más importancia a la zona de sombras y tonos medios.
Las curvas de corrección de gamma se aplican en todas las cámaras, normalmente a través de los perfiles de color (picture profile)
Los perfiles de color son configuraciones predefinidas que utiliza el procesador de la cámara para ‘cocinar’ la información del sensor. Cada configuración usa una curva de corrección de gamma y parámetros como contraste y saturación..
Los fabricantes pueden incluir en las cámaras varios tipos de perfiles:
- Perfiles basados en el espacio de color BT.709, que generan vídeo con un aspecto muy cercano al que tendrá en distribución. Es decir, se puede coger el material de la cámara y publicarlo directamente. Suelen ser los perfiles Natural, Vivid, Neutral… BT.709 es capaz de recoger un rango de 100 nits (5-7 pasos de luz)
- Perfiles cinematográficos con acabado final. Son perfiles que amplían el rango dinámico con respecto a BT.709 y lo encapsulan para dar un aspecto que simula el de una película de cine: alto rango dinámico, contraste elevado, saturación… Estos perfiles generan material para ser publicado directamente (empaquetado en el rango dinámico de BT.709) o que sólo necesita pequeñas correcciones en edición.
- Perfiles con curvas logarítmicas (S-Log, C-Log…). Estos perfiles están pensados para ofrecer el mayor rango dinámico posible en la fase de edición. Pueden recoger rangos de luminosidad por encima de 1000-1500 nits (12-14 pasos de luz para una determinada escena). Sin embargo, el vídeo resultante está ‘a medio cocinar’, el resultado es una imagen muy plana, sin contraste, y muy lavada, con muy poca saturación. Pero conserva muy bien el detalle en las sombras y en las altas luces. Esta materia prima hay que cocinarla en la fase de edición hasta conseguir el aspecto y el estilo final que se busca. Es un flujo de trabajo mucho más pesado y que requiere de conocimientos avanzados tanto en la fase de grabación (es difícil exponer fuera del espacio BT.709 a menos que se utilicen monitores especiales) y en la fase de edición (colorimetría, etc.), pero es el que ofrece más flexibilidad.
Más información (inglés): what’s the difference between latitude and dynamic range?
Calidad de vídeo y flujo de trabajo en edición
El proceso de edición puede ser muy diferente dependiendo de los objetivos del proyecto.
Como regla general interesa tener un material de grabación de partida (el material bruto, lo que nos ha generado la cámara) con la mayor calidad posible. En un mundo ideal sería material RAW que viene directamente del sensor, sin aplicar ningún tipo de curva gamma ni compresión.
¿Cuándo viene bien tener tanta información de vídeo en la fase de edición?
- Cuando necesitamos crear una imagen final con un gran rango dinámico, mucho contraste entre luces y sombras, conservando los detalles de la escena, y queremos tener nosotros el control sobre la forma de conseguir ese aspecto.
- Cuando tenemos previsto hacer una corrección de color importante o un etalonaje de la secuencia para darle un determinado look
- Cuando estamos filmando una secuencia con chroma key para ponerle un fondo en edición o para crear efectos especiales con el personaje, etc.
- Para tener más margen en caso de errores en rodaje. Por ejemplo si ha habido algún problema con la exposición de la secuencia durante el rodaje y necesitamos corregir en postproducción (levantar las sombras de una escena que nos ha quedado muy subexpuesta, recuperar luces) o si se necesitan grabar escenas muy complejas en cuanto a iluminación que llevan la cámara al límite de sus posibilidades.
- …
¿Qué es la corrección de color (color grading)?
Son procesos de edición que buscan dar al vídeo un aspecto lo más natural posible, tal como lo verían nuestros ojos en la escena real. Tiene especial importancia en lo que respecta por ejemplo a la tonalidad de la piel humana.
Entre las tareas que se realizan en este proceso estarían: corregir el contraste y la saturación, y eliminar dominantes de color no deseadas, por ejemplo si no se ha podido hacer en la fase de grabación un balance de blancos adecuado.
También se ajusta el color de las escenas para que todas ellas tengan una coherencia a lo largo del vídeo, independientemente de la hora de rodaje o de las condiciones de iluminación.
¿Qué es el etalonaje?
El etalonaje es también una corrección de color, pero buscando dar a la escena una ambientación determinada. Es decir, usando el color como parte del mensaje del vídeo, para expresar una idea o crear una sensación determinada en el espectador.
Los procesos de corrección de color son muy importantes en cualquier producción de vídeo, pero sobre todo en las producciones en las que se quiere conseguir un look cinematográfico.
Se pueden hacer todos estos procesos partiendo de cualquier material de grabación, pero cuanta más información de vídeo tengamos en la fase de edición, más flexibilidad tendremos a la hora de trabajar.
Si el material de partida ya ha sido ‘cocinado’ por la cámara, el margen de maniobra será menor.
Por el contrario, si partimos de un material sin cocinar y con mucha información tendremos una flexibilidad mucho más alta a la hora de corregir color, contraste, etc. hasta llegar al aspecto que queremos para el vídeo final, sin que aparezcan efectos no deseados.
Entre un extremo y otro hay prácticamente infinitas posibilidades en cuanto al equipo que necesitamos y la configuración de este equipo.
Comparativa de cámaras según la tasa de bits que generan
Mira la tasa de bits que ofrecen diferentes cámaras grabando en Full HD (depende de la eficiencia del codec, etc. pero por tener una idea de magnitudes) :
iPhone 6 (1080p 30fps) …….. 17Mbps High Profile H.264
Canon EOS 700D (1080p 30fps) …….. 44Mbps (IPB)
Canon EOS 80D (1080p 30fps) …….. 87Mbps (All-I)
Sony a7S II (1080p 30fps) …….. 50Mbps
Panasonic Lumix GH4 (1080p 30fps) …….. 2o0Mbps (All-I)
Blackmagic Cinema (1080p 30fps) …….. 147.2Mbps (ProRes 422)
Blackmagic Ursa (1080p 30fps) …….. 500Mbps (ProRes 444 XQ)
Arri Alexa Plus (1080p 30fps) …….. 2640Mbps (In-camara recording ProRes 444)
Y grabando en 4K:
Panasonic Lumix G7 (4K) …….. 28Mbps
Sony a7S II (4K 30fps) …….. 100Mbps
Panasonic Lumix GH4 (4K) …….. 200Mbps (All-I) / 100Mbps (IPB)
Ahora mira la comparativa de tasas de bits para diferentes formatos de distribución de vídeo:
youtube.com ………. 8 Mbps (Full HD)
DVD ………. 5-8 Mbps
Blu-ray ……. 54Mbps
TV Full HD (DVB-T España) < 20Mbps (depende de cada canal de TV)
Resumen y conclusiones
Sobre la calidad global de un vídeo
La calidad de un vídeo tiene que ver con el contenido de ese vídeo, la historia que cuenta y cómo la cuenta. Tiene que ver con la música y el sonido. Tiene que ver con la parte artística. Tiene que ver con la iluminación… Y al final de toda esa cadena estaría la parte técnica, los criterios de calidad de imagen.
Sobre el volumen de información y los sistemas de compresión
- Cuando grabamos vídeo se genera una cantidad de información enorme.
- Para hacer viable el almacenamiento y gestión de la información de vídeo se utilizan varias técnicas de compresión.
- Las técnicas de compresión intentan eliminar información redundante o aprovechan las características de la visión humana para dejar sólo información que permita reconstruir el vídeo sin pérdida de calidad apreciable.
- Algunas técnicas de compresión: sin pérdida de información (lossless), intraframe, interframe (long GOP), submuestreo de crominancia, curvas de corrección de gamma…
- Los formatos de compresión son algoritmos (p.e. h.264)
- Los codecs son implementaciones de esos algoritmos (p.e. Quicktime h.264, x264…)
- Los contenedores son ficheros que encapsulan los componentes de un vídeo: información de vídeo, de audio, metadatos, subtítulos.. También se les llama formatos (por la extensión del fichero: MP4, MOV…)
- El vídeo final no necesita un volumen de información enorme para ser visualizado con una calidad aceptable (youtube: 8Mbps, DVD: 8Mbps, TV: 20Mbps, Blu-ray: 50Mbps)
- En la fase de edición es donde se necesita más volumen de información (materia prima), dependiendo de lo agresiva que vaya a ser dicha edición (corrección de color, etalonaje, efectos especiales…)
- Trabajar con más información de vídeo implica aumentar costes. Más dinero en equipo, más tiempo, y se necesitan más conocimientos técnicos.
Sobre las cámaras (equipo en general)
- Las cámaras de vídeo especializadas, de gama alta, con sensores Super 35, etc. Generan un volumen más grande de información (materia prima más pura), y en general dan más flexibilidad en todas las fases del flujo de trabajo. Pero hay que tener conocimientos avanzados para sacar partido a todas sus posibilidades.
- Las diferencias en el resultado final, entre lo que se puede conseguir con una cámara de gama media y una cámara especializada de gama alta, son relativamente pequeñas en la mayoría de las situaciones. Pero las cámaras avanzadas pueden cubrir situaciones más complicadas de iluminación o escenas para integrar con efectos especiales, donde las cámaras de gamas más bajas no llegan.
- A partir de una cierta gama de cámaras, por ejemplo réflex y mirrorless de gama media, incluso cámaras compactas de gama media alta… Se pueden hacer proyectos de vídeo impresionantes.
- Todas estas cámaras (gama media hacia arriba) ofrecen calidad de imagen suficiente para la mayoría de los proyectos de vídeo que podamos imaginar. No te quedes con la idea de que hay que tener una Arri Alexa para hacer un vídeo de calidad. Quédate con la idea de que tienes que conocer las limitaciones de tu equipo actual para no sobrepasarlas, pero hasta ese punto intenta exprimir todo el potencial de tu cámara.
¿Con una cámara más avanzada conseguiremos mejores vídeos?
Depende, pero en general: NO (suponiendo que partimos de una cámara actual de gama media)
La parte técnica supone un porcentaje pequeño de la calidad global del vídeo. Una cámara con mejores prestaciones técnicas nos permitirá grabar en situaciones más complejas de iluminación o nos permitirá editar de una forma más agresiva manteniendo una buena calidad final.
Para sacar partido a una cámara más avanzada también se necesitan más conocimientos técnicos y una inversión mayor en equipo auxiliar.
¿Vale la pena comprar una cámara que no graba en 4K?
Sí. Full HD es por el momento el formato estándar de distribución de vídeo.
Sin embargo, aunque sólo publiquemos en Full HD, grabar en 4k supone como mínimo 4 veces más información de vídeo en la fase de edición. Nos da más flexibilidad para reencuadrar, aumentar, aplicar estabilización de imagen por software, etc..
Todas esas opciones se pueden hacer en la fase de grabación si lo planificamos correctamente y grabamos correctamente. Pero tienes ese margen adicional.
Como desventaja, trabajar con 4K necesita más recursos: almacenamiento, equipo de edición, tiempo..
¿Cuál sería entonces la cámara que sacaría el máximo partido de la calidad de youtube?
No hay una respuesta para esta pregunta, ya que las necesidades de la cámara o sus limitaciones nos las va a marcar la fase de grabación y sobre todo la fase de edición, en función del tipo de vídeos que pensemos hacer, y también en función de nuestros conocimientos sobre grabación y edición.
¿Cuál sería una buena cámara si queremos empezar a grabar vídeos con aspecto cinematográfico?
Como hemos comentado, cualquier cámara réflex o mirrorless de gama media ofrece calidad y flexibilidad suficiente para la mayoría de proyectos de vídeo, incluyendo este tipo de proyectos con look cinematográfico.
Dentro de las réflex, las cámaras de Canon suelen incluir características que facilitan la grabación. Cualquier réflex de Canon de gama intermedia (700D, 750D, 70D, 80D..) sería una buena elección para empezar.
Entre las mirrorless, las cámaras micro 4/3 de Panasonic dan mucho protagonismo al apartado de vídeo y podrían ser una buena elección. También las Sony (a6000, a6300…) son un buen punto de partida para vídeo.
Si tenemos un presupuesto más flexible, las Sony a7 de segunda generación (Sony a7S II, a7R II…) o la Panasonic GH4, que ha sido durante mucho tiempo la referencia en grabación en 4K.
Un salto a equipo más especializado podrían ser por ejemplo las Blackmagic
Ten en cuenta que el look cinematográfico no es sólo la cámara: es la iluminación, son los encuadres, las localizaciones, el sonido, la estabilidad de las tomas, la coherencia con la historia…
Cámaras recomendadas para vídeo para publicar en youtube