Entender los niveles de audio de una forma sencilla
Explicamos de forma sencilla la diferencia entre nivel de audio y volumen de sonido. Y los niveles óptimos para podcast, streaming, vídeo...
Sonido vs señal de audio
Esto es probablemente lo más importante que vamos a ver en este artículo. En realidad es una tontería, pero entenderlo te va a hacer comprender mejor el flujo de trabajo con el sonido.
Sonido
El sonido tiene que ver con las ondas de presión en el aire.
Nuestro oído es capaz de percibir esas ondas y nuestro cerebro las interpreta: voz, música, etc.
El volumen tiene que ver con la intensidad del sonido y cómo nuestro oído percibe esa intensidad.
En un sistema de sonido, cuando hablamos de volumen (control de volumen) nos estamos refiriendo siempre al sonido, por ejemplo el que va a salir por unos altavoces o unos auriculares.
Señal
Cuando captamos el sonido con un micrófono obtenemos una señal eléctrica (voltaje que varía según la intensidad del sonido en cada instante).
Esa señal eléctrica es una representación del sonido y recibe el nombre de audio o señal de audio (aunque coloquialmente hablamos de señal de sonido, sonido, etc. para referirnos también a la señal de audio).
La señal de audio la podemos manipular.
Por ejemplo, la podemos amplificar o atenuar. Esto lo controlamos con la ganancia.
La amplitud de la señal es variable, ya que responde a las variaciones del sonido original, pero normalmente sólo nos interesan parámetros más globales como la amplitud máxima (picos) o la amplitud media (RMS por ejemplo).
Cuando trabajamos con la señal de audio hablamos normalmente de niveles de audio.
La señal de audio puede ser analógica o digital.
Aunque hay diferencias entre una señal analógica y una digital, lo importante es entender que son representaciones de un sonido.
En la parte digital se sigue hablando de ganancia y niveles.
Resumen:
-
Sonido Onda de presión La intensidad sonora tiene que ver con la amplitud de las ondas El volumen tiene que ver con la percepción en nuestro oído El volumen lo gestionamos en un dispositivo con el control de volumen
-
Señal de audio Es una representación analógica (voltajes) o digital (números) de un sonido Podemos amplificar o atenuar la señal de audio Los niveles de la señal los gestionamos mediante el control de ganancia
Seguro que estás pensando que todo eso parece un poco pedante y que no deja de ser nomenclatura. Pero ahora veremos por qué es útil disociar el sonido de su representación.
La cadena de sonido
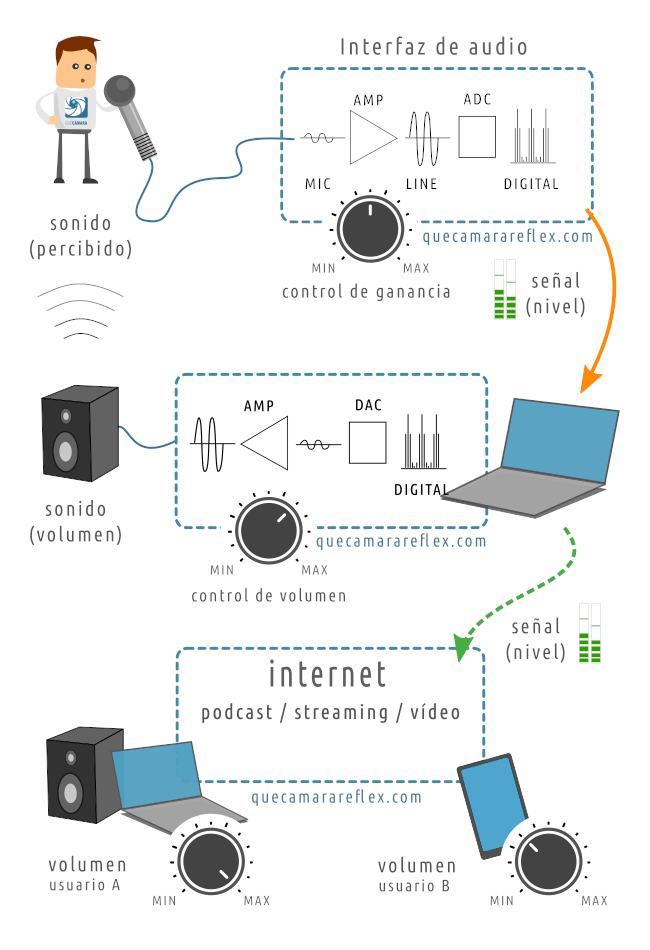
El término ‘cadena de sonido’ hace referencia al camino que sigue el sonido desde que lo captamos con un micrófono hasta que lo reproducimos en unos altavoces o auriculares.
La mejor forma de visualizarlo es con un ejemplo sencillo, pero este ejemplo es la base del 99% de las situaciones que nos vamos a encontrar en la producción y difusión de audio.
Imagina que queremos emitir en directo, a modo de podcast en vivo o haciendo streaming de vídeo, o una videoconferencia… nos da igual porque en este caso nos vamos a quedar sólo con la parte de audio.
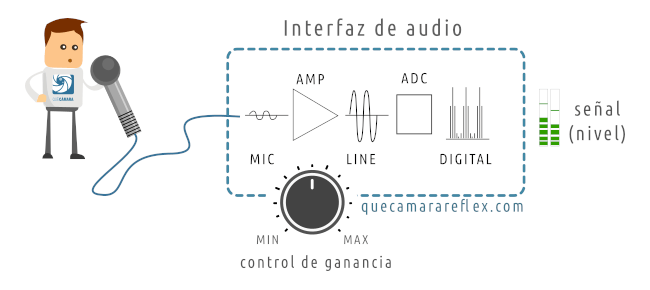
Nuestra voz (sonido) es captada por el micrófono y se convierte en una señal eléctrica.
Esa señal es muy muy débil y la llevamos a un preamplificador para aumentar su nivel. Por ejemplo vamos a suponer que estamos usando una interfaz de audio externa.
Ajustamos el nivel de la señal mediante el control de ganancia de la interfaz.
La interfaz está conectada al ordenador. Ahí tendremos nuestros programas para emisión o para grabación de sonido, que utilizarán la señal de audio digital que recibimos de la interfaz.
Esa señal tiene un determinado nivel.
Vamos a suponer que para oírnos a nosotros mismos, para comprobar qué tal se oye, tenemos conectados unos cascos o un altavoz al ordenador.
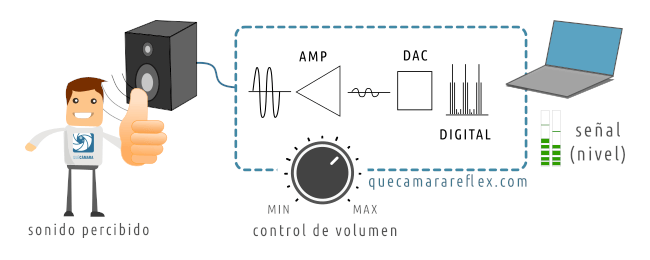
Es importante entender que aunque las imágenes son similares, este segundo escenario representa otra parte de la cadena del sonido, la reproducción. Partimos de un audio digital y lo convertimos en sonido.
En la imagen lo he representado con un altavoz para que se vea un poco mejor esa transformación de la señal de audio en sonido, en la práctica sería mejor utilizar unos auriculares cuando estamos grabando con un micrófono, para evitar acoples (realimentación), ecos y otros efectos no deseados.
El volumen del sonido que sale por el altavoz (o auriculares) lo regulamos con el control de volumen del ordenador o con el control de volumen de los altavoces / auriculares.
Fíjate que en ese escenario tan sencillo podemos tener muchísimas combinaciones de ganancia y volumen para las que tendríamos una percepción del sonido muy similar.
Por ejemplo, podríamos tener la ganancia de la interfaz cerca del mínimo. El nivel de la señal sería bajo. Pero luego podemos compensar con el volumen de los altavoces.
O podríamos tener la ganancia de la interfaz más alta, por ejemplo en la zona media de su rango. Y luego podemos compensar bajando el volumen de nuestros altavoces.
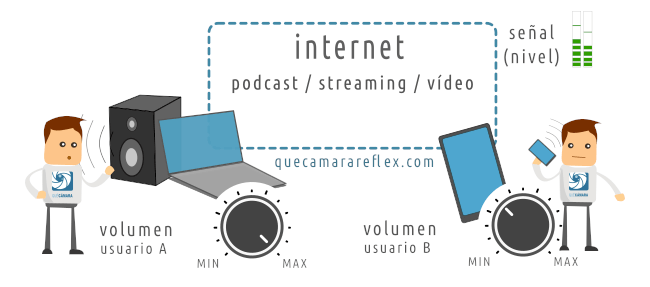
Imagina ahora qué puede ocurrir con la señal de audio que estamos transmitiendo a través de internet.
Cada persona que nos esté escuchando tendrá un equipo diferente, con diferentes altavoces, amplificadores, etc.
Además cada persona tendrá diferentes preferencias en cuanto al volumen al que quiere escuchar nuestra voz. Y cada persona tendrá una capacidad auditiva diferente… Y estará en un ambiente diferente: en casa, en mitad de la calle, conduciendo en el coche…
Ninguna de esas personas va a percibir el sonido con la misma intensidad (volumen) al que lo estamos escuchando nosotros cuando monitorizamos con los cascos o los altavoces.
La conclusión es que el sonido no nos sirve como referencia absoluta.
Por otra parte tenemos que la señal que se transmite es digital: son números.
No hay atenuación debida a la transmisión. Todos ellos van a recibir la misma señal, con los mismos niveles que estamos emitiendo.
Los niveles de la señal sí son una referencia absoluta.
Luego, cada uno de los oyentes hará lo que quiera con esa señal: elegirá el volumen más apropiado para escucharla. Eso ya no depende de nosotros. Pero podemos ofrecerles una señal con los niveles óptimos.
Cuando transmitimos audio en directo o cuando publicamos un vídeo o un podcast… Lo importante son los niveles de la señal de audio. No es importante cómo oímos nosotros mismos ese sonido en nuestro equipo.
Por ejemplo, imagina que transmites tu audio con un nivel muy bajo.
Es posible que tú oigas perfectamente el sonido de tu voz en tus auriculares porque tienes un buen equipo y has subido mucho el volumen. Pero quizás otra persona no pueda reproducir ese sonido porque está utilizando un móvil, sin auriculares, en un entorno de ruido ambiental, etc.
Y en todo caso es muy incómodo para el usuario tener que estar cambiando constantemente el volumen porque cada podcast, cada streaming o cada vídeo envía el sonido con un nivel totalmente diferente.
Gestionar el nivel de audio
Para todo lo que hagamos que tenga que ver con emisión o publicación de sonido: siempre, siempre, siempre hay que tener una referencia objetiva del nivel de la señal de audio final.
Nuestros cascos o altavoces no son una referencia objetiva.
Utiliza siempre una referencia visual, un medidor de los niveles de la señal.
Vamos a trabajar en un entorno digital, por lo tanto hay que acostumbrarse a la escala digital y a los decibelios.
No vamos a entrar en detalles, pero para que tengas una idea orientativa sobre los decibelios y la escala dBFS:
Los decibelios: dB
Son un truco matemático.
Nos facilitan el cálculo cuando trabajamos con amplificación / atenuación, porque en lugar de multiplicar y dividir sólo tenemos que sumar (ganancia) y restar (atenuación o ganancia negativa)
Y por otra parte representan mejor las escalas que tienen que ver con la percepción del sonido (logarítmica en lugar de lineal, ya que el oído tiene una respuesta logarítmica)
Aquí tienes más información sobre los decibelios en sonido y audio.
La escala digital: dBFS
dBFS viene de: decibels relative to Full Scale.
Es una escala de niveles (de señal) acotada a un valor máximo: 0dB.
Ese valor máximo de 0dB se corresponde con el valor máximo que puede representar la señal digital trabajando con una determinada codificación.
Por ejemplo, si usáramos valores (números) de 8 bits, el valor máximo que se puede representar sería 255 (0dB en la escala dBFS)
Cuando trabajamos con audio digital no hay nada por encima de 0dB en la escala dBFS.
Todos los niveles de nuestra señal tienen que estar por debajo de ese techo. Los valores válidos son siempre negativos.
El límite inferior estaría acotado por el número de bits que estemos usando en la codificación, pero en un entorno real el límite inferior está acotado por el nivel de ruido electrónico (noise floor)
Lo importante aquí es que si por algún motivo entra un sonido cuyo nivel de audio supera los 0dB, la señal resultante quedará recortada (no hay nada por encima de 0dB).
Se produciría lo que se conoce como hard clipping, clipeo, recorte… que se traduce en una distorsión profunda de la señal de audio y daría como resultado un sonido desagradable.
Medir los niveles de la señal de audio
Históricamente, cuando la señal de audio era totalmente analógica, se utilizaba un vúmetro, un dispositivo físico (en inglés es VU meter, donde VU significa Volume Unit). Más abajo comento un poco sobre los vúmetros.
En la actualidad toda la gestión es digital (salvo entornos muy concretos) y lo que vamos a usar normalmente son medidores digitales, que nos representan de forma visual los niveles de la señal (en decibelios) sobre una escala dBFS.
Para grabación y monitorización en general nos interesa sobre todo el medidor de pico (peek meter) con el que podemos ver en tiempo real cómo cambian los niveles de la señal.
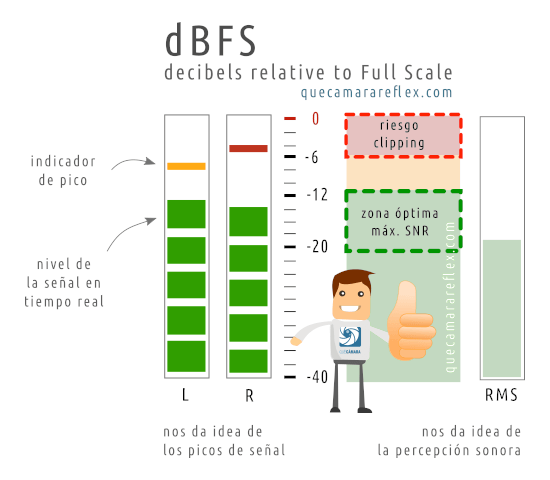
Nuestro objetivo será ajustar la ganancia a lo largo de la cadena de audio para que los niveles estén en una zona alta en la escala dBFS pero sin que en ningún momento lleguemos a 0dB (en ninguno de los elementos de la cadena).
El 99.9% de las veces vas a usar un medidor de pico.
Si por el motivo que sea tu software de grabación te muestra un medidor RMS (que sería como una especie de valor medio): mira en las opciones para cambiar la configuración o intenta usar otro medidor que te ofrezca los niveles de amplitud .
Un medidor RMS puede ser útil en la fase de edición, porque da una idea más precisa de cómo se va a percibir ese audio cuando alguien lo reproduzca en sus altavoces (percepción del volumen o intensidad sonora), pero para grabación y emisión en directo es mejor tener la variación instantánea.
¿Cómo usamos el medidor de niveles de audio?
Más abajo veremos diferentes escenarios.
Pero en general nos centraremos sobre todo en dejar un margen suficiente en la parte de arriba (headroom o techo dinámico de la señal) para evitar que cualquier pico de sonido inesperado nos genere distorsión por clipeo.
El recorte o clipeo es el enemigo número 1 de la calidad de sonido en el mundo digital.
Implica una saturación destructiva de la señal (la señal queda recortada a 0dB, ya no que puede superar ese valor), y se percibirá como un sonido distorsionado muy desagradable.
Tenemos que dejar los picos máximos se señal (por ejemplo cuando hablamos más fuerte) siempre por debajo de esa zona de clipeo. Y además, como suele ser muy difícil prever el nivel exacto de esos picos hay que dejar un cierto margen de seguridad.
La mayoría de los medidores nos dan información sobre el pico máximo que se ha producido durante un cierto período.
En algunos casos aparece como una barrita solitaria que se queda flotando durante unos segundos en ese nivel máximo.
En otros medidores también se nos muestra el nivel máximo absoluto que ha alcanzado la señal durante la grabación de esa toma.
Si se ha producido recorte de la señal (clipeo) la mayoría de los medidores nos dan algún tipo de aviso visual, por ejemplo se enciende algún aviso en rojo.
Algunos medidores nos pueden mostrar cuánto nos hemos pasado. Nos mostrarán un valor positivo, por ejemplo +2.1dB. Recuerda que ese valor no existe en la escala dBFS, pero nos sirve de referencia para saber que tendremos que reducir la ganancia al menos en esa cantidad para evitar que vuelva a distorsionar.
Como regla genérica, esos picos máximos poco frecuentes los podríamos tener controlados en el entorno de -6dB en grabación.
Para la señal de audio que corresponde con el sonido normal que vamos a grabar, por ejemplo nuestra voz, nos podríamos quedar en la zona de -12dB a -20dB, que sería el rango en el que podemos conseguir una buena relación señal a ruido.
No hay una regla fija o unos valores exactos, porque al final depende del tipo de sonido y su rango dinámico (la diferencia entre los sonidos más débiles y los más fuertes).
Más abajo vemos cómo gestionar el nivel de audio en algunos escenarios de uso típicos.
Niveles de referencia de audio (señal analógica)
Esto sólo es importante a la hora de conectar cables… Lo vamos a comentar de forma muy resumida simplemente para que te suene.
Aquí tienes un poco más de información sobre los niveles de entrada: Mic, Line, Inst…
Los equipos de audio trabajan con diferentes tipos de señales. Cada entrada de un equipo ‘espera’ o está preparada para un determinado nivel de señal. Hablamos de señales analógicas y los niveles a los que nos referimos normalmente son para valores RMS (valores eficaces).
-
Entrada MIC Nivel de señal muy muy pequeño. Sólo para conectar micrófonos
-
Entrada de línea (LINE) Es digamos un nivel estándar con el que pueden trabajar e interactuar todos los equipos de audio que trabajan con señal analógica. En el mundo profesional el nivel de línea es de +4 dBu (aprox. 1.23 V RMS) Para los equipos de electrónica de consumo es de -10 dBV (aprox. 0.33 V RMS)
-
Entrada de instrumento (Inst / Hi Z) No tiene que ver con niveles exactamente, sino con un tipo de señal específica de ciertos instrumentos (guitarras eléctricas, bajos, etc.) que no corresponde con las características de MIC ni de LINE.
Como digo, no te tienes que preocupar de estos niveles, sólo hay que tenerlo en cuenta para conectar cada elemento a la entrada que le corresponde en un equipo de audio (p.e. en una interfaz o una mesa de mezclas).
Una vez que la señal se ha pasado a digital los valores y niveles son absolutos, referenciados a la escala dBFS. Da igual si se han generado en un micrófono, una guitarra eléctrica o vienen de un archivo MP3.
Medir nivel de la señal en analógico - vúmetro
Este apartado sólo lo incluyo como curiosidad o por si tu equipo analógico (por ejemplo una mesa de mezclas) incluye un vúmetro real.
No quiero liar con esto. Si no aplica en tu caso (p.e. si utilizas un micrófono USB o una interfaz de audio sin vúmetros) puedes saltar este apartado directamente.
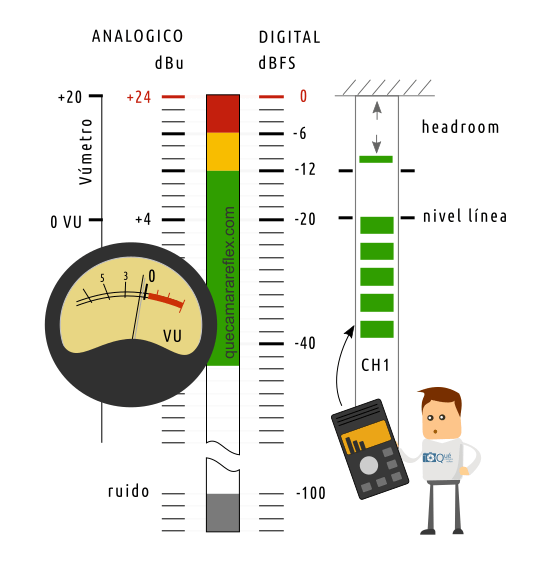
Por resumirlo de una forma sencilla, podríamos decir que el vúmetro mide la energía de la señal analógica (de forma similar al valor RMS), una especie de valor medio integrado durante un período de tiempo.
En la señal de audio, el valor medio (energía si lo queremos pensar así) está muy por debajo del valor de pico. Por ejemplo en una señal de voz típica, la diferencia entre valores medios y valores de pico ronda los 15dB.
El cero del vúmetro representa el nivel de línea (por ejemplo +4 dBu en equipos de audio profesional).
En esa zona alrededor del cero del vúmetro conseguimos una buena relación señal a ruido y tenemos un buen margen de seguridad (headroom).
El headroom típico en la mayoría de los equipos analógicos es de unos 20dB. Es decir, tenemos mucho margen para absorber cualquier pico de sonido elevado sin que llegue a distorsionar.
Por eso, trabajando con un vúmetro, el nivel de referencia del audio lo situaríamos en esa zona del cero (sería como el nivel óptimo). Aquí, en analógico, sí que podemos pasar de cero sin distorsión. Pero teniendo en cuenta que no vemos los picos, sólo vemos la variación de un valor medio. Cuanto más nos pasemos del cero, más riesgo de que un pico llegue a saturación (distorsión).
En la imagen de arriba tienes una representación de las tres escalas: la escala del vúmetro, la escala de niveles dBu y la escala dBFS. La escala dBFS puede estar calibrada de forma diferente según el equipo, por ejemplo el valor de 0 VU (cero del vúmetro) puede estar calibrado a -18dBFS o a -20dBFS, etc.
Tomando como referencia la imagen, si tenemos un vúmetro en la parte analógica, sería la escala de la izquierda (un vúmetro analógico de aguja, o un vúmetro de tipo barra con luces de colores, etc.) Si tenemos medidor sólo en la parte digital, entonces sería la escala de la derecha, la escala dBFS que ya hemos comentado.
¿Por qué cuento todo esto?
Porque si usas una mesa de mezclas (o algún otro dispositivo que trabaje con audio analógico), encontrarás posiblemente escalas que superan los 0dB: en el medidor de nivel del bus principal, en los faders de mezcla, etc.
En esos casos sólo hay que pensar que el cero de esas escalas correspondería más o menos con unos -20 dBFS (de la parte digital).
Es decir, son escalas que representan el nivel de la señal, pero medido de forma diferente, y representado de forma diferente.
Niveles óptimos de audio
A partir de aquí siempre voy a hablar de señal digital de audio y por lo tanto de escala dBFS. Todo lo que comento aplicaría igualmente si usamos vúmetro en la parte analógica, pero ajustando a su escala.
Siempre se trata de intentar alcanzar un equilibrio entre mantener la señal de audio en un nivel razonable para maximizar la relación señal a ruido y jugar con el riesgo de que un pico de sonido nos pueda producir distorsión por clipeo.
Entonces vamos a plantear diferentes escenarios.
1. Grabamos voz para vídeo o podcast
No emitimos en directo, por lo tanto tenemos la opción de editar y ajustar un poco el sonido antes de publicar.
En este caso yo intentaría trabajar en una zona segura, alrededor de la zona de -12dB a -20dB para el audio que corresponde a la voz normal podría ser una buena referencia.
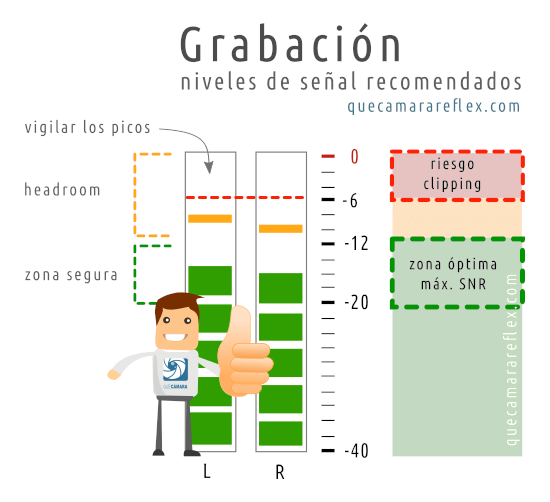
Hacemos primero una prueba de sonido, con las mismas condiciones con las que vamos a hacer la grabación: posición del micrófono y la fuente de sonido, la intensidad de voz normal con la que vamos a hablar, la intensidad máxima de voz que podríamos alcanzar (gritos, risas, etc.)…
Ajustaríamos la ganancia de la interfaz de audio (o la ganancia que corresponda dependiendo de tu equipo) para que esos picos máximos queden dentro de la zona de seguridad de los -12dB.
Para una voz hablada normal podríamos tomar también como referencia que la señal ‘pique’ sobre los -15dB (para la voz con la intensidad normal, sin gritos, etc.). Si gritamos en algún momento o subimos la intensidad de voz, tendríamos margen suficiente por arriba.
En esa zona de trabajo, la mayoría de los equipos de sonido ofrecen un buen rendimiento en cuanto a relación señal a ruido (buena calidad de audio).
Una vez tengamos ajustada la ganancia en la prueba de sonido: la intentamos dejar fija durante la sesión de grabación, para facilitarnos el trabajo en la fase de edición y procesado. Si vemos durante la grabación que no hemos estimado bien y que estamos en el límite de llegar a la zona de clipping, pues ajustamos la ganancia, no pasa nada.
Con esa configuración de ganancia deberíamos tener un techo dinámico de seguridad por encima, que pueda aguantar cualquier sonido más fuerte de lo previsto.
Es importante que estos valores que comento no los tomes como una receta universal o como algo obligatorio. No hay recetas universales. El equipo, el lugar de grabación, las características de la voz, el tipo de contenido… son infinitas combinaciones.
Lo importante es entender qué estamos haciendo y por qué lo hacemos. De esa forma podrás adaptar la configuración a cada situación concreta.
Por ejemplo, si el sonido que grabas tiene pocas variaciones de intensidad (poco rango dinámico) se puede apurar un poco más.
La marca de los -6dB podría ser una referencia en esos casos. Pero teniendo cuidado con los picos máximos, porque te arriesgas a estropear una grabación por no haber dejado margen suficiente.
Terminada la sesión de grabación tendremos el fichero (o los ficheros) de audio, en formato WAV por ejemplo, dependiendo del programa de grabación o de tu equipo (grabadora digital, cámara, etc.). Es aconsejable que hagas una copia de seguridad de esos originales.
El audio que hemos grabado tendrá unos niveles muy bajos (es lo que queríamos) y no nos valdría tal cual para publicar o distribuir.
Pasamos entonces a la fase de edición.
Todos los programas de edición de audio tienen herramientas y módulos parecidos. Tendrías que mirar, para tu programa en concreto, cómo hacer estas operaciones. Pero son procedimientos relativamente sencillos (al menos para unos criterios de calidad aceptables). Como digo, lo importante es saber qué estamos haciendo.
Aunque en este capítulo hablamos sobre todo de niveles, voy a plantear un pequeño flujo de trabajo de edición que podría ir bien en la mayoría de los casos (recuerda que no hay recetas universales):
-
Echamos un primer vistazo a la señal Para ver si hay picos exagerados y vemos a qué corresponden (p.e. un golpe sin querer al micrófono, palmadas / claqueta para separar tomas, etc.). Si no corresponden al contenido final, cortamos y eliminamos ese trozo de audio o reducimos su nivel (atenuamos) para que no afecte a la normalización ni a otros procesos.
-
Normalizamos el nivel Normalizar el nivel consiste en amplificar toda la señal de forma lineal. No modifica las características del sonido ni sus niveles relativos. Si por ejemplo tienes varias tomas grabadas con diferente ganancia, podrías ajustar a ojo el nivel de cada trozo, para que toda la sesión quede con un nivel homogéneo. O puedes usar un módulo de normalización, pero aplicado inicialmente a cada trozo. El módulo de normalización nos suele preguntar el techo máximo, es decir, hasta dónde puede llegar el pico máximo de la señal. Podemos normalizar por ejemplo a -3dB o a -6dB. Dejamos ese pequeño margen por si otros módulos del flujo de trabajo añaden ganancia adicional.
-
Edición La edición propiamente dicha: cortar trozos de audio que no nos interesan, acortar silencios, eliminar tomas falsas, sincronizar audio y vídeo (si fuera el caso), unir los audios de varias tomas, etc.
-
Limpieza / reducción de ruido Aplicaríamos primero un módulo de reducción de ruido (patrón estadístico) Luego podríamos aplicar una puerta de ruido (sólo actúa sobre los tramos de silencio) Mira más abajo el apartado de limpieza de sonido / reducción de ruido.
-
Ecualizador Esto sería para usuarios que tengan un poco de experiencia y conocimientos. Si no, es mejor no tocar, porque es muy fácil estropear el audio.
-
Compresor Por ejemplo en casos donde tengamos un rango dinámico muy amplio: p.e. imagina que tenemos desde susurros hasta gritos en una misma sesión. El compresor reduce los picos máximos para igualar un poco los niveles. También hay que usarlo con mucho cuidado. Si no conoces bien el funcionamiento, yo recomendaría utilizar algún módulo sencillo, que tenga pocos parámetros de configuración y, a ser posible, que incluya configuraciones predefinidas para elegir ‘voz hablada’ o la que más se asemeje al tipo de grabación.
-
Otros procesos Por ejemplo, si vamos a incluir música, o varias pistas de audio, etc. Lo que sería la parte de mezcla.
-
Normalizamos el nivel Volvemos a normalizar. Ahora la señal que corresponde a la mezcla de todas las pistas (voz, música, etc.) y para conseguir el nivel de pico deseado. Por ejemplo, podemos normalizar a -1dB, o a -2dB o a -3dB… dependiendo de la plataforma donde vayamos a publicar o nuestro propio criterio.
-
Normalizamos el volumen En este paso lo que haremos es ajustar el nivel ‘medio’ de nuestra sesión en cuanto a sonoridad / volumen (la percepción de volumen de sonido que tendrá la persona que lo escuche) Esto está relacionado con los LUFS (más abajo lo comento).
-
Exportamos al formato de publicación
Sobre la normalización en volumen.
La sonoridad del audio está relacionada con la percepción humana.
Señales con niveles similares pueden sonar (las percibimos) con volúmenes totalmente diferentes. Esto tiene que ver con la energía que transportan las ondas de sonido en función de su frecuencia, duración, etc. y con la respuesta en frecuencia del oído humano y su adaptación dinámica a la intensidad de los sonidos.
Para la normalización en volumen lo ideal sería utilizar un medidor LUFS (Loudness Unit Full Scale), que nos va a permitir ajustar la sonoridad de tal forma que:
-
Cumpla con los requisitos de la plataforma en la que vamos a publicar Por ejemplo en youtube la señal de audio debería estar como máximo en -14 LUFS con picos siempre por debajo de -1 dB Las plataformas de podcast suelen trabajar con -16 LUFS con picos hasta -1 o -2 dB como máximo …
-
Mantener una consistencia en los niveles de audio de cada episodio, vídeo, etc. Una consistencia entre nuestros propios episodios / vídeos para que el usuario final tenga la mejor experiencia posible. Es molesto tener que ir ajustando el volumen para cada nuevo capítulo o episodio (unos se oyen muy bajo, otros muy alto, etc.)
Si tu software de edición de audio no tiene un medidor de LUFS o no te quieres complicar la vida: con la normalización en nivel creo que podría valer perfectamente para voz hablada en la mayoría de los casos.
También puedes tomar como referencia los niveles RMS para hacerte una idea.
La mayoría de los programas de edición de audio incluyen medidor RMS o algún módulo que permite calcular este parámetro para el audio final.
Si tu programa de edición incluye un módulo de gestión de LUFS (medidor + ajuste automático) sería la opción más rápida y sencilla.
En estos módulos podemos indicar exactamente los valores que queremos:
- Sonoridad: LUFS, p.e. -16dB dependiendo de la plataforma
- Valores pico máximo (true peak), p.e. -1dB o -2dB dependiendo de la plataforma
Y el módulo se encarga de ajustar la señal de audio a esos niveles.
Estos módulos actúan como una especie de compresor ‘inteligente’ y normalizador de nivel.
En general debería ser un proceso bastante transparente, no debería afectar mucho a la señal (excepto en la sonoridad).
Ten en cuenta que estos módulos pueden tener un margen de tolerancia. La idea es que nuestro audio final, el que vamos a publicar, esté por debajo del límite que impone la plataforma pero que no estemos muy alejados.
Por ejemplo, si vamos a publicar en youtube (-14 LUFS máx.) nuestro audio se va a escuchar perfectamente bien en cuanto a volumen si estamos en el rango de -14 LUFS a -20 LUFS.
Si nos pasamos de los límites (el techo máximo), la plataforma aplicará sus propios automatismos y ajustará los niveles a su manera, y ahí ya no tenemos ningún control sobre el resultado final.
Si tu programa de edición no tiene un módulo de normalización en volumen (sonoridad / loudness / LUFS), puedes tomar como referencia el nivel RMS medio y puedes ajustar la sonoridad un poco a ojo utilizando un compresor.
Con el compresor puedes reducir de forma automática los picos máximos de una forma suave. Y eso da espacio por arriba para amplificar toda la señal en conjunto.
Dicho de otra forma: por un lado atenuamos los picos máximos y compensamos subiendo la ganancia a toda la señal.
Lo podemos imaginar como que estamos aumentando la energía total de la señal, y esto lo vamos a percibir como más sonoridad cuando pasamos la señal a sonido.
Jugando con el compresor y con la normalización en nivel (dejando los valores pico máximo dentro del límite de la plataforma) podemos conseguir una normalización en volumen aceptable.
No hay que obsesionarse con esto.
El objetivo es dejar un nivel de audio aceptable para que el usuario final tenga una buena experiencia (por ejemplo que no tenga que subir al máximo el volumen de su dispositivo para poder escucharnos).
No tiene sentido que nos pasemos con el compresor y ‘estropeemos’ la señal por cumplir exactamente con unos criterios de sonoridad.
2. Emitimos voz en directo
Por ejemplo si hacemos streaming de vídeo o podcast en vivo.
En este escenario no tenemos posibilidad de editar el sonido a posteriori.
Tenemos que buscar una configuración en tiempo real que se acerque a la que tendríamos al publicar.
Nuestro principal enemigo sigue siendo la distorsión por recorte digital (clipping).
Pero por otro lado, si nos quedamos en la zona más segura, como hacíamos en grabación, vamos a emitir posiblemente con un nivel un poco bajo y vamos a obligar a los usuarios a subir el volumen en sus equipos.
Lo que se suele hacer en estos casos es subir la ganancia para alcanzar un nivel de audio un poco más agresivo para el tono de voz normal, hacia la zona de los -10dB / -6dB podría ser una buena referencia, vigilando que los picos no lleguen a los 0dB.
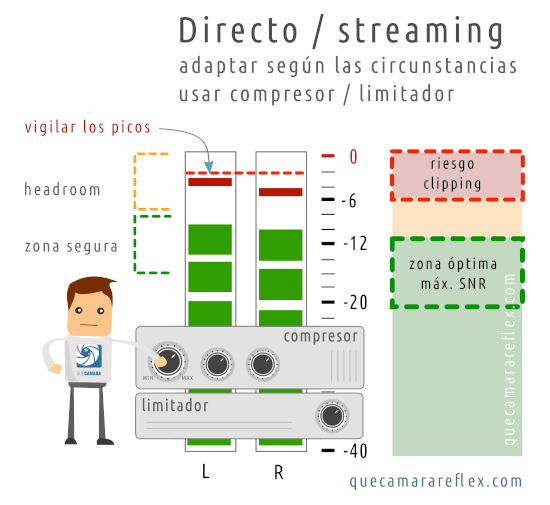
Y si el software que estemos utilizando para la gestión del audio lo permite, sería interesante añadir algún filtro o plugin de seguridad: un compresor para equilibrar un poco los niveles de la señal (comprime el rango dinámico) y un limitador (un compresor más agresivo) para evitar que los picos de sonido más fuertes nos lleven a la zona de clipeo y distorsionen el audio.
Tanto los compresores como los limitadores manipulan la señal y por tanto cambian las características del sonido final.
Hay que buscar un equilibrio entre los niveles originales y los parámetros de funcionamiento de estos filtros.
Dependiendo de la potencia de tu equipo, de las características del programa que utilices para gestionar la emisión (p.e. OBS) y de otros factores, podrías incluir en tu flujo de procesamiento de sonido procesos similares a los que comentamos en edición, por ejemplo podrías intentar configurar un flujo de este tipo:
-
Reducción de ruido
-
Puerta de ruido
-
Ecualización
-
Compresor
-
Limitador
En tiempo real no hay mucho margen y lo importante es conocer todos los elementos de la cadena para poder ir ajustando sobre la marcha, dependiendo de la situación.
Los propios usuarios te pueden dar información y avisar si hay algo que no está bien. Pero ten en cuenta que cada usuario tendrá una percepción diferente. Tu principal referencia será siempre el medidor de nivel de salida (dBFS).
3. Streaming con voz + música + sonidos de un juego + …
Seguiríamos la misma estrategia que comentamos en el apartado anterior.
Pero en este caso hay que tener en cuenta también la relación entre los niveles de las distintas fuentes de audio.
Normalmente la voz tiene el protagonismo, y ajustaríamos los niveles para la zona más alta, añadiendo compresor / limitador si fuera necesario.
La música de fondo tendría que ir en un nivel mucho más bajo para que la voz se perciba correctamente y destaque sobre ese fondo.
Una separación de 10 / 15dB podría ser un buen punto de partida, pero depende de la música el tipo de voz, etc.
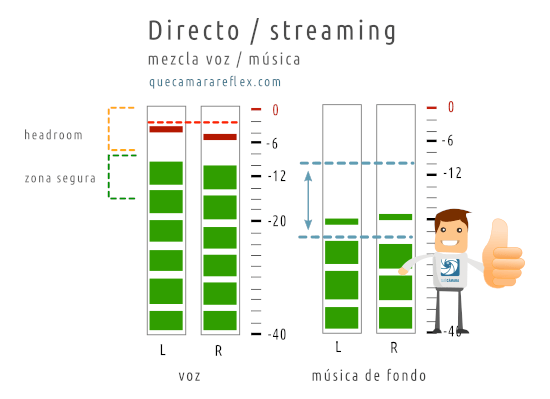
Por ejemplo, si tenemos la señal de voz en una media de -10dB, la música de fondo intentaríamos llevarla a unos -20dB o -25dB de media.
Para los sonidos de un juego es mucho más subjetivo porque depende de la importancia que le quieras dar al juego con respecto a la voz, del tipo de juego (por ejemplo si hay explosiones, o sonidos muy fuertes, etc.)
Es cuestión de encontrar el equilibrio más adecuado en cada caso.
Puedes mirar también la opción de ‘ducking’ si tu software de emisión incluye esta posibilidad.
Ducking es una automatización que consiste en que cuando hay un cierto nivel de una fuente de audio (p.e. nuestra voz) todas las demás fuentes de audio o alguna en concreto (p.e. la música de fondo) son atenuadas para dar protagonismo a la fuente principal.
Ten en cuenta también que si usamos varias fuentes de sonido, todas ellas contribuyen al nivel de la mezcla final (master) que es la que vamos a emitir.
Limpieza / reducción de ruido
Dentro del saco de ‘reducción de ruido’ entran muchos conceptos y fuentes de ruido diferentes.
Esto es sólo una introducción para que te suene alguno de estos conceptos.
Digamos que el ruido puede ser sonido captado por el micrófono (el ventilador del ordenador, el vecino cantando, la moto de turno, el sonido de la respiración entre frases..) o ruido electrónico generado en el proceso de grabación.
Para los ruidos con un patrón más o menos constante (ruido electrónico, ventilador…) se suele usar algún módulo de reducción de ruido estadístico.
El módulo nos pide que seleccionemos un trozo de audio que corresponde a un silencio (sin voz, sin música, etc.)
Lo analiza, y aplica los algoritmos de reducción a toda la secuencia de audio, incluyendo tanto los tramos de silencio como los tramos con señal (contenido).
Suelen tener algún parámetro para ajustar su ‘agresividad’.
Si el módulo es muy agresivo modificará de forma perceptible la señal (puede sonar como artificial o con artefactos extraños). Si es muy poco agresivo, dejará parte del ruido.
En cada caso hay que buscar ese equilibrio que nos dé una señal lo más limpia posible, con un ruido que apenas se perciba en los tramos donde hay señal (por ejemplo que no se perciba cuando se escucha la voz).
En los tramos de silencio entre frases, entre palabras, etc. es donde más se suele percibir el ruido.
Para limpiar esos tramos se puede utilizar una puerta de ruido (noise gate).
Con la puerta de ruido lo que hacemos es que si la señal está por debajo de un cierto nivel (durante esos tramos de silencio), la puerta se cierra y no deja pasar nada.
Por ejemplo, podríamos configurar la puerta para que el nivel de sonido de la respiración quede por debajo del límite de detección de la puerta.
En ese caso, al aplicar la puerta a toda la secuencia de audio, los tramos de silencio quedarían limpios, planos.
La puerta de ruido limpia todo, incluyendo el ruido electrónico, pero sólo en los tramos de silencio.
Como los módulos de reducción de ruido (estadísticos) necesitan información de ruido en esos tramos de silencio, la puerta de ruido tiene que ir después del módulo de reducción de ruido en el flujo de trabajo.
Y, como ocurre con todos estos módulos, la puerta de ruido no hace magia, es una automatización.
Si la configuramos mal (un nivel o unos parámetros muy agresivos) puede afectar a la señal. Y tampoco puede garantizar que limpie todas las respiraciones por ejemplo o todos los sonidos ambiente (una moto, el avión o la ambulancia que pasó en ese momento). Todos esos sonidos que están a un nivel de señal comparable a la del contenido real, van a pasar la puerta y van a quedar tal cual. Los tendríamos que limpiar a mano uno por uno.
Y muy importante: la puerta de ruido no limpia nada dentro de los tramos con señal.
Todos los ruidos que se hayan colado mientras suena nuestra voz o el instrumento que corresponda, van a seguir ahí.
Esos sonidos ambiente no deseados captados por el micrófono son muy difíciles de eliminar en la fase de edición (salvo casos muy concretos en los que el sonido sigue algún patrón temporal, p.e. un ventilador).
Lo ideal sería intentar que el micrófono no capte ese tipo de sonidos: colocando el micrófono cerca de la fuente de sonido si es posible, aprovechando el patrón polar del micrófono (cardioide, etc.) para que las zonas de menor sensibilidad apunten a la fuente de ruido, buscando un lugar lo más aislado posible del ruido ambiente, etc.
Más información sobre sonido:
Todos los artículos sobre grabación y tratamiento de sonido
Cómo mejorar la calidad de sonido para vídeo / streaming
Estudio básico de grabación de vídeo para YouTube / streaming
Cámaras recomendadas para vídeo (para youtubers, vlogs, etc.)
Cámaras recomendadas para streaming / emisión en directo
Sobre niveles, cables, y conceptos de audio profesional
Micrófonos de estudio recomendados (+Interfaz de sonido)
Micrófonos USB de estudio recomendados